Data in the iron mask: How to protect important and sensitive information
🎭 This is a special post co-authored with Matthew Yerbury and Nicholas Biller, friends from HSBC’s People Data Science team. We use a Hollywood film from the 1990s to introduce the concept of data masking in a fun way!1
In The Man in the Iron Mask film, King Louis XIV was kidnapped, put in an iron mask, and replaced by his secret identical twin brother. Putting King Louis behind the mask kept his identity hidden—until the mask was unlocked by a key.
This story can help us understand the concept of data masking, which involves hiding and replacing original data with a scrambled copy. Just like how no one could identify King Louis because his most important features were hidden behind a mask.
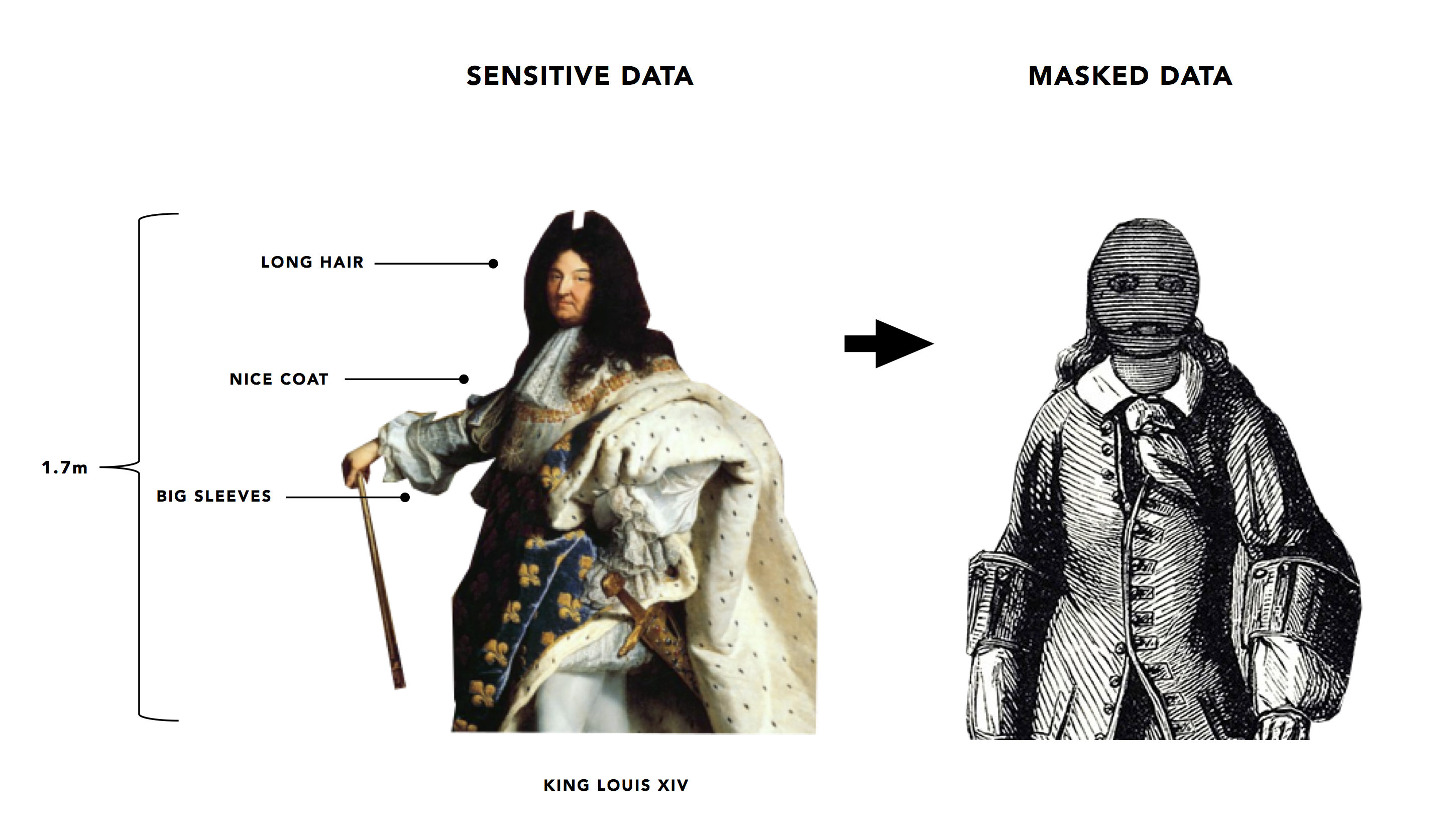 Original images from: Wikimedia Commons, Alamy
Original images from: Wikimedia Commons, Alamy
In this post, we introduce the basics of data masking. We share some common data masking techniques and a simple flow chart to help practitioners consider when and which masking techniques may be needed.
Why mask data?
Data are masked to protect important but sensitive personal information. Companies have to follow strict legal regulations and ethical obligations surrounding how they use and share sensitive personal data to respect peoples’ right to anonymity.
As more companies move towards storing data in the cloud, they need to make sure that sensitive customer or employee information remain protected.
Data masking methods
Data can be masked using anonymisation or pseudonymisation techniques, depending on the level of data protection needed.
Anonymisation is an irreversible process where the original information, or its granularity, is lost. This is like throwing away the key to unlock the King’s iron mask. These are some examples of anonymisation techniques.
| Technique | Description | Before Example | After Example |
|---|---|---|---|
| Adding noise | Add known levels of inaccuracy to data | Savings £23,034 £94,304 £25,153 |
Savings £24,943 £94,502 £24,205 |
| K-aggregation | Rolls up data into groups, summarising rows in minimum sample size K | Location London Birmingham Sheffield |
Location UK *K=3 |
| Generalisation | Converts values into categories | Location London Birmingham Sheffield |
Location UK UK UK |
Pseudonymisation is a reversible process where the original information is preserved. This has fewer limitations on data analysis but is less secure because a key file that maps the original values to the masked values must be saved separately.
This is like having a key to unlock the iron mask. These are some examples of pseudonymisation techniques.
| Technique | Description | Before Example | After Example |
|---|---|---|---|
| Hashing | Converts data into a random character sequence that is difficult to reverse without the key |
Location London Birmingham Sheffield |
Location 59ead8d1e1242 269cb914b20d2 30d85fa7d5632 |
| Substitution | Replaces original values with alternative values | Location London Birmingham Sheffield |
Location Giraffe Eagle Mercedes |
| L-Diversification | Splits each attribute into L different values | Location London |
Location Giraffe Springbok Bison *L=3 |
2Note: Each hashed location actually has 32 characters but only the first 12 characters are displayed in the table.
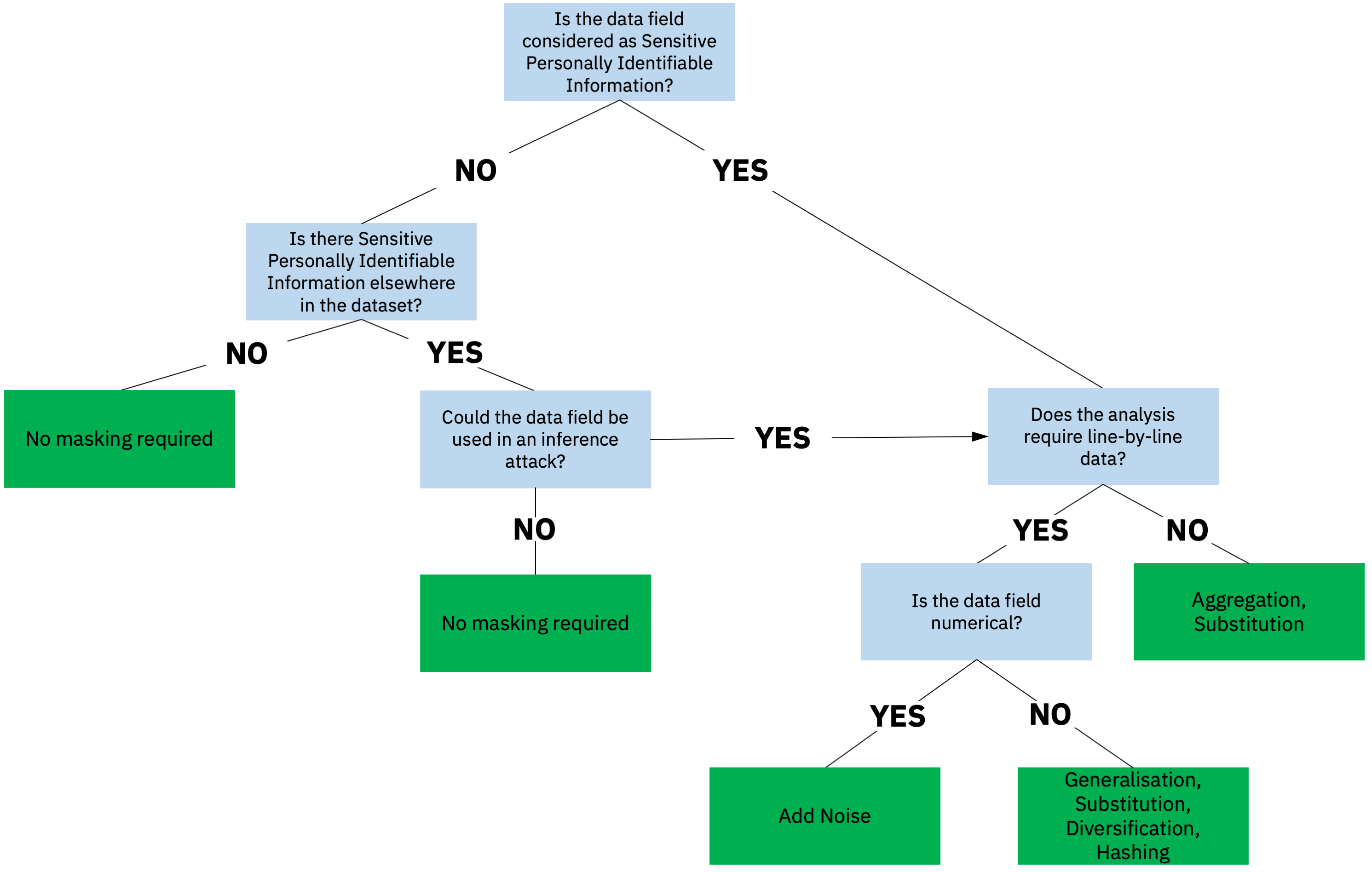
When and how to mask your data
This is a simple flow chart to help you start thinking about when and which masking techniques may be needed for your project.
Summary
Data masking is like The Man in the Iron Mask, you hide sensitive and important information behind a mask. It’s difficult to identify what’s behind the mask without unlocking it with a key. Companies need to mask important and sensitive personal information for privacy reasons, especially as they move towards storing data in the cloud. We’ve shared some data masking techniques and considerations for choosing appropriate techniques.
P.s. We wanted to use this image of King Louis but couldn’t afford the copyright fees (click to see) 🙂
{kind=link}
About the authors: Kenneth Lim is a Data Scientist with IBM’s Data Science Elite team, Nicholas Biller is the Senior People Data Science Lead at HSBC, Matthew Yerbury is the Group Head of People Data Science at HSBC.↩